Get To Know More
I'm Vedant Sanjay Chavan, an AI & Computer Vision Engineer specializing in 3D perception, deep learning, and real-time vision systems. I’ve worked on stereo vision and adaptive perception algorithms at FORVIA HELLA, developing lightweight CNNs and synthetic datasets for automotive AI. With an M.Eng. in Mechatronics and experience across machine learning, geometry, and generative AI, I focus on building intelligent systems that bridge the physical and digital worlds — from autonomous perception to industrial inspection.
Core Expertise
Browse My Recent
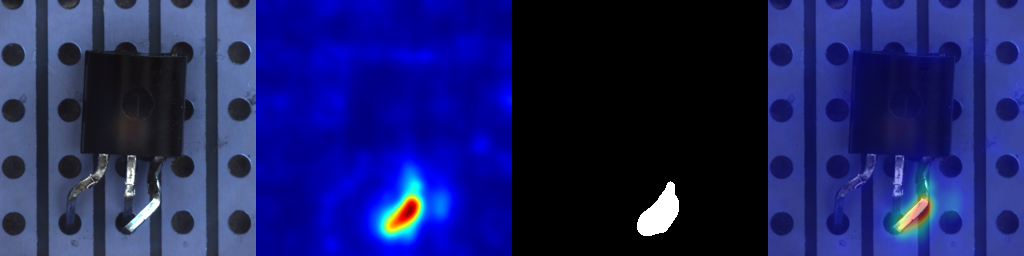
Developed perception models for adaptive headlights using stereo vision and deep learning. Improved night-time detection accuracy by 30% and achieved real-time 3D localization with embedded GPUs.




Improve night-time perception for adaptive headlights by enabling reliable object detection and lane understanding under glare, rain, and low-illumination conditions.
This work was presented to the R&D and perception teams at HELLA and influenced ongoing ADAS prototype development.
Tech Stack: Python · PyTorch · OpenCV · YOLOv8 · DeepSORT · ONNX Runtime · Docker · Stereo Calibration · Triangulation
Built a lightweight stereo CNN for long-range depth estimation and 3D object localization. Generated 9,000+ synthetic pairs in Unreal Engine 5 and optimized inference latency to 70 ms.





Develop a lightweight deep-learning model for dense depth estimation and 3D object localization in adaptive headlight control.
This work was presented to the R&D and perception teams at HELLA and influenced ongoing ADAS prototype development.
Tech Stack: PyTorch · YOLOv8 · Unreal Engine 5 · OpenCV · CUDA · ONNX Runtime · Docker · Calibration QA · Synthetic Data Generation
Tech: ABB AC800M PLC, PLC Programming, HMI (SCADA), Industrial Automation
Browse My Recent

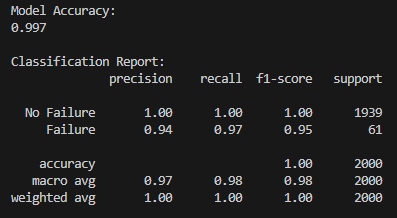
Developed a custom YOLO model for detecting objects in bin picking tasks, achieving 98% precision in 6D pose estimation.

Built a lightweight stereo CNN for adaptive headlights — achieving 95% depth accuracy at 30m and 3% D1-all on KITTI.

Converted monocular smartphone video into a dense 3D scene using COLMAP preprocessing and Gaussian Splatting rendering.
Additional Skills
C1
B1
Fluent
Courses
Get in Touch